

What do DynamoDB, Apache Cassandra, Discord, Akamai CDN and Amazon Web Services have in common. They all use consistent Hashing. We'll undersand why do they use it and why is it needed.
In large scale distributed system, data doesn't fit on a single server. They are distributed across many machine, which you may know as horizontal scaling. To build such a system with a predictable performance, it is important to distribute the data evenly across those server.
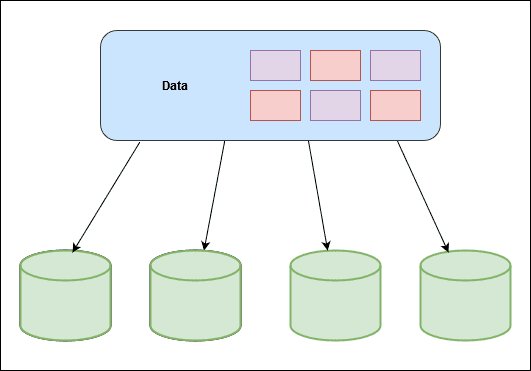
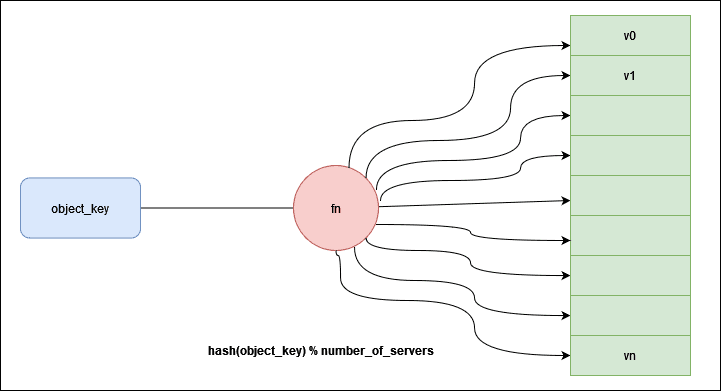
A common method to distribute data as evenly as possible among server is simple hashing. This is how it works. First, for each object, we hash its key with a hashing function. First for each object, we hash its key with a hashing function like MD5 or MurmurHash. This maps the object key to a known range of numerical values. A good hashing function distributes the hashes evenly across the entire range.
serverIndex = hash(key) % N
# Where 'N' is the size of the server pool.
Second, we perform the modulo operation on the hash aganist the number of server. This determines which servers the object belongs to. As long as the number of server stays the same, and the object key will always maps to the same server. Here's an concrete example:
We have 4 servers with 8 string keys with simple hashing this is how we distribute the eight string keys among the 4 servers. Now, this approach works well when the size of the cluster is fixed, and the data distribution is even. But what happens when a new server hets added to meet the demand or when exisiting server gets removed? So to handle this, if anyone server goes down, the size of ther cluster is now 3. Even though, the hashes for the object stays the same, we are now applying the modulo operation to a different set of N. In this case, it is now three. the impact is pretty drastic. Most of the keys gets redistributed. This affects all objects, it's not just the objects originally stored in the server that is now offline. This triggers a storm of misses and lots of objects to be moved. For situations where servers constantly come and go, this design is untenable.
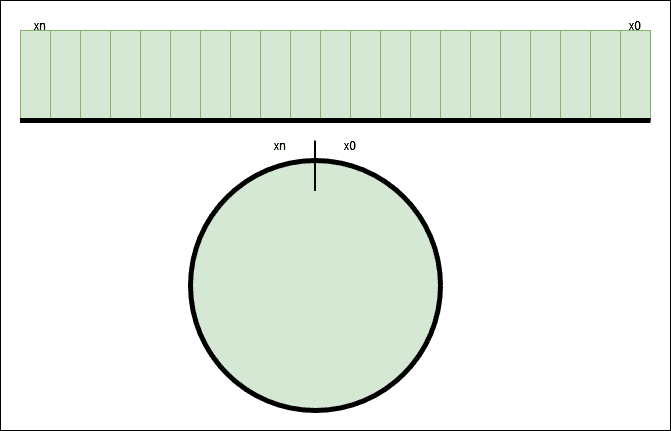
Consistent hashing is an effective technique to mitigate this issue. The goal of consistent hashing is that, we want almost all the objects to stay assigned to the same server even as the number of server changes. This is the main essence of consistent hashing. In addition to hashing the object keys like before, we also hash the server names. The objects and serversare ahshed at the same hashing function to the same range of values. In our example, we have a range of x0......xn. This range is called a hashspace. Next, we connnect both ends of the hashspace to form a ring. This a hash ring.
- With simple hashing, when a new server is added, almost all the keys need to be remapped.
- With Consistent Hashing, adding a new server only requires redistribution of a fraction the keys.
Using this hash function we hash each server by its name or IP address, and place the server onto the ring. Here, we place our 4 server onto the ring. Next, we hash each object by its key with the same hashing function. Unlike, simple hashing where we perform modulo operation on the hash, here we use the hash directly to the map the object onto the ring. Here is what it would look like for our 4 objects.
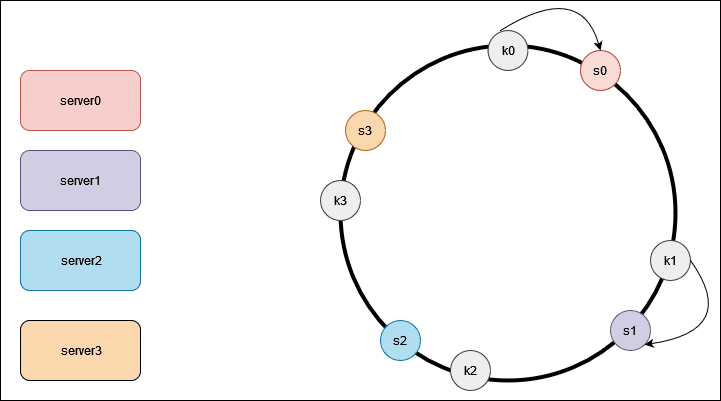
To locate the server for a particular object, we go clockwise from the location of the object key on the ring until a server is found. Lets continue with our example , key k0 is on server s0, and key k1 is on server s1. Now, lets take a look at what happens when we add a server. Here we insert a new server s4 to the left of s0 on the ring.
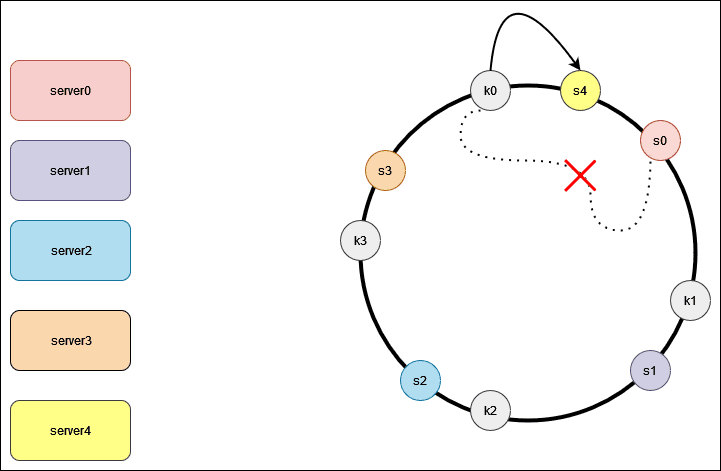
Lets suppose, when server s1 is removed,only key k1 needs to be remapped to server s2. Then rest of the keys are unaffected. What we know so far is that, we map both servers and the object onto the hash ring using a uniformly distributed hash function. Moreover, to locate a server for an object, we go clockwise on the ring from the object position until a server is found.
The potential problem with this design is that, the distribution of the object in the servers on the ring is likely to be uneven. Conceptually, we pick N random points on the ring, we are very likely to get a perfect partition of the ring into equally sized segments. Like when the servers are mapped on the ring like the diagram below.
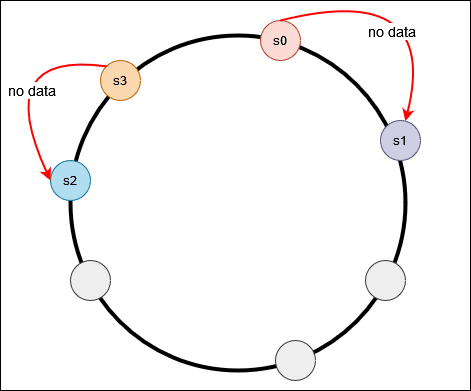
Most of the objects are stored in s2, with s1 and s3 storing no data. This problem gets worse if servers come and go frequently. To counter this, Virtual node are used to fix this problem. The idea is to have each server appear at multiple location on the ring. Each location is a virtual node representing a server.In this hash ring, we are having 2 servers, eith each ahaving three virtual nodes. Instead of having s0and s1, where server s0 are represented as s0_0, s0_1, s0_2 and server s1 is represented as s1_0, s1_1, s1_2 on the ring. With virtual nodes, each server handles multiple segments on the ring. In the examples, the segments labeled s0 are managed by server s0, and server s1 repectively.
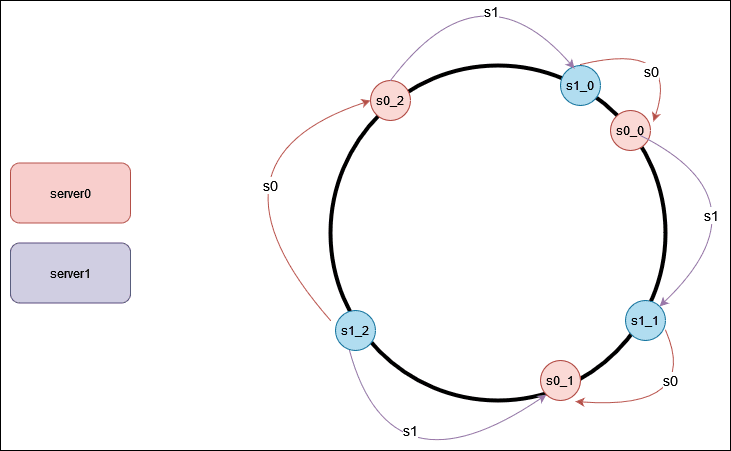
In real world systems, the number of virtual nodes is much higher than as shown. As the number of virtual nodes increases, the distribution of the objects becomes more balanced. Having more virtual nodes means taking more space tothe meatdata about the vitual nodes. Well, this a trade-off, and we can tune the numberof virtual nodes to fit our system requirements.
Popular NoSQL databases like Apache Cassandra and Amazon DynamoDB uses Consistent Hashing, where it is used for the data partitioning. It helps these databases minimises data movement during rebalancing. Content delivery Like Akamai CDN, CLoudflare or GoogleCloud CDN uses consistent hashing to help distribute web contents evenly among the edge servers. Load balancers like Google LoadBalancer use consistent hashing to distribute persistent connection evenly across backend servers. This limits the number of connections that needs to be re-established when a backend server goes down.
Although Load Balancing is a key concept to system design. It is the most popular way to balance the load in a system. The reason we're interested in distributed dictionaries is because they're used as input and output to the MapReduce framework for distributed computing. Ofcourse, that's not the only reason – they’re also critical for many other usages like distrbuted caching. Consistent hashing isn’t the final word in distributed dictionaries, but it’s a good start.
After getting an overall understanding of the basics for consistent hashing, there are many follow-ups questions like- whats the best way to cope up with different sizes of the servers, how to add and remove more than one machine at a time, how to cope up with fault tolerance, how to migrate data when jobs are going on including backups. Hopefully it'll get easier to answer these type of question at this point.
Let's finish up with the history of consistent hashing. It was introduced in 1997, in a pair of papers, describing on the applications of caching on the world wide web, not to distributed computing like MapReduce. It is widely used in popular memcached caching system and Amazon's DynamoDB key-value store.
That's it for Consistent Hashing, see you in the next one.
References:
https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.23.3738
https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.23.3738